鵝廠分享 從初創到成熟,一款App需要分析哪些核心數據及如何構建數據處理服務

在移動互聯網競爭激烈的今天,數據驅動決策已成為產品成功的基石。無論是初創團隊驗證想法,還是成熟產品優化增長,一套清晰的數據分析體系與強大的數據處理服務都至關重要。本文將以騰訊(鵝廠)的實踐經驗為參照,梳理一款App在不同發展階段需要關注的核心數據指標,并探討如何構建與之匹配的數據處理服務體系。
一、不同發展階段的核心數據分析重點
1. 初創期 (0-1,驗證與留存)
此階段的目標是驗證產品核心價值,找到早期種子用戶并讓他們留下來。數據分析應聚焦于最基礎的指標,避免過度復雜。
- 核心價值指標: 功能使用深度、核心路徑轉化率。例如,對于一個社交App,是“成功發布動態/完成一次聊天”的比例;對于一個工具App,是“核心功能任務完成率”。
- 用戶獲取與質量: 渠道來源分析、用戶畫像(基礎屬性)。關注哪個渠道來的用戶留存更高、更活躍。
- 留存與活躍: 次日/7日/30日留存率 是生命線。需要分析新用戶的初始行為與長期留存的關系。日活躍用戶(DAU)、周活躍用戶(WAU)的絕對數及趨勢。
- 問題發現: 崩潰率、關鍵操作錯誤率、用戶反饋(評論、工單)的文本分析。
2. 成長期 (1-100,增長與規模化)
產品價值得到驗證后,重點轉向快速增長和規模化獲取用戶。數據分析需更精細化,支持增長實驗。
- 增長漏斗分析: 從市場曝光→下載→激活→注冊→首次關鍵行為→持續活躍的全鏈路轉化分析。定位流失環節。
- 用戶分群與行為分析: 對用戶進行更精細的分群(如新老用戶、渠道、版本、行為特征群組),對比不同群組的留存、活躍和付費情況。分析用戶行為序列和生命周期。
- A/B測試與實驗數據: 任何產品功能、UI/UX、運營策略的改動,都應通過A/B測試評估其對核心指標(如留存、轉化)的影響。
- 營收與商業化數據(如果適用): 付費用戶數(APA)、付費率、平均每用戶收入(ARPU)、平均每付費用戶收入(ARPPU)、生命周期價值(LTV)。
3. 成熟期 (規模化運營,效率與生態)
用戶規模趨于穩定,重點轉向提升運營效率、深化用戶價值、構建生態和防御競爭。
- 生態系統健康度: 用戶互動網絡指標(如社交App的好友密度、互動頻率)、內容生態指標(如內容生產與消費比、優質內容占比)。
- 深度參與與流失預警: 用戶參與度分層(如高價值用戶、沉默用戶、流失風險用戶)。構建流失預警模型,提前干預。
- 運營效率與ROI: 各渠道、各運營活動的投入產出比(ROI)精細化核算。用戶分層的精準營銷效果分析。
- 市場份額與行業對標: 通過第三方數據或市場調研,監控自身產品的市場份額、用戶心智份額,并與競品對標。
- 長期趨勢與歸因: 分析DAU/MAU(粘性比率)、營收等核心指標的長期趨勢,并進行多維度的歸因分析(如功能迭代、市場活動、季節性因素)。
二、支撐數據分析的數據處理服務架構
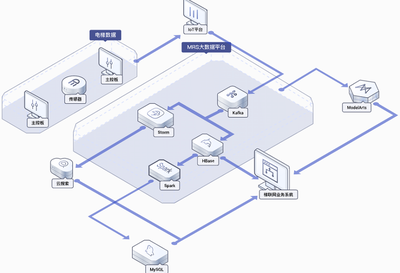
無論處于哪個階段,穩定、高效、靈活的數據處理服務是獲得可靠洞察的前提。一個典型的數據處理服務棧(參考業界及鵝廠實踐)包含以下層次:
1. 數據采集與埋點
工具與規范: 建立統一的埋點規范與管理平臺(如騰訊的MTA、神策、GrowingIO等類似工具),確保數據口徑一致。涵蓋全端(iOS、Android、Web、小程序等)自動化采集與手動埋點。
關鍵: 事件設計(Event)、用戶標識(UID)、上下文屬性(Properties)的清晰定義。在初創期就應打好基礎,避免后期重建數據。
2. 數據接入與傳輸
* 服務: 使用高可用的數據收集網關(如基于Nginx/OpenResty自研或使用Flume、Logstash),通過SDK將數據實時或批量傳輸到數據中心。保障數據不丟失、低延遲。
3. 數據存儲與計算
實時數據流: 使用Kafka、Pulsar等消息隊列承接實時數據流,供實時監控和實時計算(如Flink、Spark Streaming)使用,用于實時大盤、反作弊、即時推送等場景。
批處理與數據倉庫: 原始日志存入HDFS或對象存儲(如COS/OSS)。通過ETL(Extract-Transform-Load)流程,使用Hive、Spark、Flink等計算引擎進行清洗、關聯、聚合,并分層(ODS原始層、DWD明細層、DWS匯總層、ADS應用層)存入數據倉庫(如Hive、ClickHouse、騰訊TDW等),形成主題明確、易于查詢的數據模型。
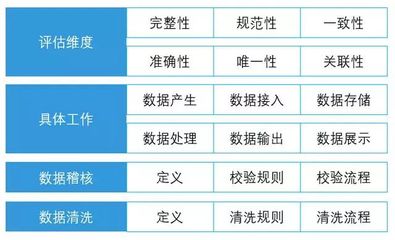
4. 數據管理與治理
元數據管理: 記錄數據表的來源、含義、血緣關系(從采集到報表的完整鏈路),方便團隊協作和數據發現。
數據質量監控: 對數據完整性、準確性、及時性設置監控告警(如每日數據量波動、關鍵字段空值率)。
* 權限與安全: 嚴格的數據訪問權限控制,遵守GDPR等數據隱私法規,對敏感數據脫敏。
5. 數據應用與服務
分析平臺: 提供靈活的可視化報表(如自助BI工具Tableau、帆軟、騰訊云圖)、OLAP查詢引擎(如Presto、Kylin、ClickHouse)和用戶行為分析平臺(如神策、GrowingIO的深度替代或自研),供產品、運營、分析師自主探索數據。
數據服務化(Data API): 將清洗后的關鍵數據(如用戶標簽、實時指標)通過API或數據總線的方式,提供給推薦系統、廣告系統、風控系統、客服系統等業務系統實時調用。
* 算法模型平臺: 為流失預測、用戶分層、個性化推薦等高級分析提供數據特征和模型訓練/部署支持。
###
從初創到成熟,App數據分析的焦點從 “驗證價值、關注留存” 轉向 “驅動增長、優化漏斗” ,最終達到 “提升效率、經營生態” 。而底層的數據處理服務,則需要從一開始就具備 可擴展、規范化和高可用 的架構視野,從埋點規范做起,逐步構建起從采集、傳輸、存儲、計算到應用的全鏈路能力。
鵝廠的經驗表明,數據建設并非一蹴而就,它需要與產品發展同步規劃、持續迭代。初期可以借助成熟的第三方服務快速啟動,但在規模擴大后,擁有自主可控、深度定制化的數據中臺和能力,往往是構筑長期競爭優勢的關鍵。記住:你無法優化你無法衡量的東西。 盡早并持續地關注正確的數據,并投資于可靠的數據基礎設施,將為你的App成功鋪平道路。
如若轉載,請注明出處:http://m.tjsdjyxy.cn/product/16.html
更新時間:2026-05-10 23:08:04