華為云MapReduce服務 功能優勢解析與上云無憂的數據處理實踐
在當今數據驅動的時代,企業面臨著海量數據處理的嚴峻挑戰。傳統的數據處理架構往往在擴展性、成本和運維復雜度上捉襟見肘。華為云MapReduce服務(MRS)應運而生,作為一款全托管的企業級大數據處理平臺,它旨在為企業提供一站式、高性能、安全可靠的大數據解決方案,真正實現“上云無憂,數據處理服務”。
一、服務簡介:企業級大數據處理的云上基石
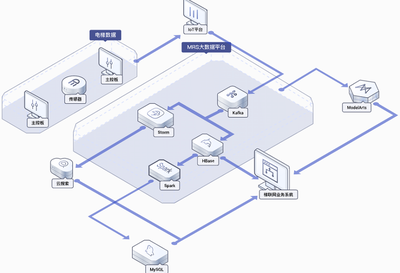
華為云MapReduce服務是一個基于開源生態(如Apache Hadoop、Spark、Flink、HBase、Kafka等)構建的云原生大數據集群。它并非簡單地將開源組件搬運上云,而是深度融合了華為云的基礎設施優勢與多年的大數據技術積淀,提供了開箱即用、彈性伸縮、運維簡化的全托管服務。用戶無需關心底層基礎設施的部署、監控、擴容與升級,可以專注于業務邏輯與數據分析本身,極大降低了大數據平臺的技術門檻和運維成本。
其核心在于提供了一個統一的計算引擎和存儲框架,能夠對PB級甚至EB級別的數據進行批處理、交互式查詢、實時流處理以及機器學習等多種計算。通過MRS,企業可以快速構建數據倉庫、用戶畫像、實時推薦、日志分析、風險控制等多種大數據應用。
二、核心功能優勢:為何選擇華為云MRS?
- 全托管與極致彈性:MRS提供完全托管服務,從集群創建、組件配置、監控告警到版本升級,全部由華為云自動化完成。其彈性伸縮能力尤為突出,可根據業務負載(如CPU/內存使用率、作業隊列長度)自動增加或減少計算節點,實現資源的按需使用和成本優化,從容應對業務高峰與低谷。
- 高性能與開源兼容:服務底層基于華為云高性能計算(ECS)、存儲(OBS)和網絡,并對開源組件進行了深度優化,在相同資源配置下能獲得更優的計算性能。它100%兼容開源接口,確保現有的Hadoop/Spark生態工具、作業和代碼可以平滑遷移上云,保護企業已有投資,實現無縫過渡。
- 企業級安全與可靠性:安全是企業上云的生命線。MRS提供多維度的安全保障:
- 網絡安全:支持VPC隔離、安全組、細粒度的IP白名單控制。
- 數據安全:支持數據傳輸與靜態加密(集成KMS)、細粒度的權限訪問控制(Ranger/Kerberos)。
- 容災與高可用:核心組件均采用高可用部署,數據支持多副本存儲,并結合華為云跨可用區(AZ)部署能力,提供金融級的數據可靠性與業務連續性保障。
- 運維智能化與成本透明:提供可視化的集群監控大盤,關鍵指標一目了然。內置智能運維助手,可對集群健康狀態進行診斷,提供優化建議。成本管理清晰透明,用戶可詳細查看資源消耗情況,結合彈性伸縮有效控制總體擁有成本(TCO)。
- 豐富的組件與生態集成:一站式集成Hadoop、Spark、Flink、Hive、HBase、Kafka、Presto等數十種主流大數據組件,并支持與華為云數據倉庫DWS、數據湖探索DLI、AI平臺ModelArts等服務的無縫對接,輕松構建從數據接入、處理、存儲到分析與智能化的完整數據流水線。
三、典型場景案例:上云無憂的數據處理實踐
場景一:離線數據倉庫與批量分析
某大型零售企業需要每日分析前一天的全國銷售數據、庫存情況和用戶行為,生成各類報表供管理層決策。傳統自建Hadoop集群資源利用率低,擴容周期長。遷移至華為云MRS后,利用其Hive/Spark組件構建云上數據倉庫。每日凌晨,通過定時作業自動從業務數據庫同步數據至MRS HDFS,執行復雜的ETL和聚合分析任務。借助彈性伸縮功能,在數小時的作業執行期間自動擴容計算資源,任務完成后自動縮容,分析效率提升50%,整體成本下降約30%。
場景二:實時流處理與風險監控
一家金融機構需要實時處理每秒數萬筆的交易流水,進行反欺詐和異常交易監測。他們使用MRS提供的全托管Flink服務,構建實時流處理管道。交易數據通過Kafka實時接入,Flink作業進行實時規則計算、特征提取和模型推理(集成ModelArts),毫秒級內識別風險交易并告警。MRS保障了Flink作業的高可用與Exactly-Once語義,運維團隊無需深入Flink底層,即可保障7x24小時的關鍵業務穩定運行。
場景三:交互式查詢與數據探索
互聯網公司的產品運營團隊需要即時查詢海量用戶日志,進行靈活的數據探查和問題定位。基于MRS部署的Presto或Impala服務,他們可以直接對存儲在OBS(對象存儲)或HDFS中的原始或預處理數據執行亞秒級到秒級的交互式SQL查詢,快速獲得洞察,而無需等待漫長的ETL和報表生成流程。存儲與計算分離的架構,使得數據可被多個計算引擎共享,資源利用更高效。
###
華為云MapReduce服務通過將復雜的大數據平臺管理任務轉化為簡單的云服務,賦予了企業敏捷、經濟、安全的數據處理能力。無論是從零開始構建大數據平臺,還是將現有本地Hadoop集群遷移上云,MRS都提供了平滑的路徑和強大的支撐。其“上云無憂”的核心承諾,正助力越來越多的企業擺脫基礎設施束縛,釋放數據潛能,專注于業務創新與價值創造。在數字化轉型的浪潮中,華為云MRS無疑是企業構建數據競爭力的可靠云上基石。
如若轉載,請注明出處:http://m.tjsdjyxy.cn/product/25.html
更新時間:2026-05-10 05:29:06